Skip to content
勿以技术论学识
“勿以技术论学识。”
这是我刚踏入职场,第一个大佬给我的忠告
很多时候,你让不同的人写同样几行代码,实现一个小功能。对一些人来说,这只是“CRUD”,只是按部就班完成任务。但对另一些人来说,他们脑子里同时在考虑各种场景、分析抽象模型,思考底层原理和扩展性。并不是说第二类人只是用“高大上”的概念包装自己,而是他们的思维方式本身就不同。我们需要去理解他们是怎么想的,为什么会这么想,这就是所谓的思维方式
想提升技艺,就必须找高手切磋。下过棋、打过球的人都知道,只有在和高手对弈或切磋的过程中,你才能真正感受到他们的方法和技能,有时甚至会情不自禁地惊呼:“哇,原来还能这样玩!
我写下这些,是因为我意识到,每个人对技术的理解会受到背景、经验、接触时间长短、媒体影响等多种因素的影响。这些观点可能正确,也可能不完全对。要真正成长,我们需要主动接触那些对技术有热情、真正厉害的人。他们可能就在你身边,也可能在开源社区里。通过关注他们如何分析问题、他们关注的点是什么,并思考他们为什么会这么看问题,你可以快速提升自己的能力
这样做不仅能拓展视野,更能锻炼你的思维方式,让你在很多场景下触类旁通,而不是单纯通过看书、刷视频而停留在原地踏步。正如老祖宗所说:“兼听则明,偏听则暗”
正确地看待框架
我在大二的时候开始接触各种的框架,接触到的框架都是 Java 生态圈的,例如 Spring, Hibernate, Struts 等。有些现在已经不入流,各路开发对其嗤之以鼻。对于这些框架的学习无非就是记住许多的"步骤",按部就班,例如 SSH 框架怎么搭建、怎么往 Spring 容器里整个 Bean
结果导致大多数人就开始觉得学技术就是学各种个样的框架,越多越好,根据一些教程,按部就班地做,如果整套步骤你能了然于胸,那你总有一天就会成为技术大牛
更可笑的是使用百度搜索关键词,诸如"如何配置 Spring 声明式事务",各种网友纷纷给出自己的"独门秘方",放着框架的文档在哪不去查。我想可能的原因就是大部分开发在刚开始学习技术的时候,英文水平都不咋滴,我也是其中一个
疫情发生前,团队都居家办公了一段时间。那时候的第一个星期,大佬安排我们去研究 Spring 的官方文档,然后把看到的内容进行总结。刚开始,我的思维还停留在“步骤”上:怎样配置 Bean、声明式事务该怎么用等,以前学的一套套教程、操作流程,在我脑中都是碎片化的、机械的操作
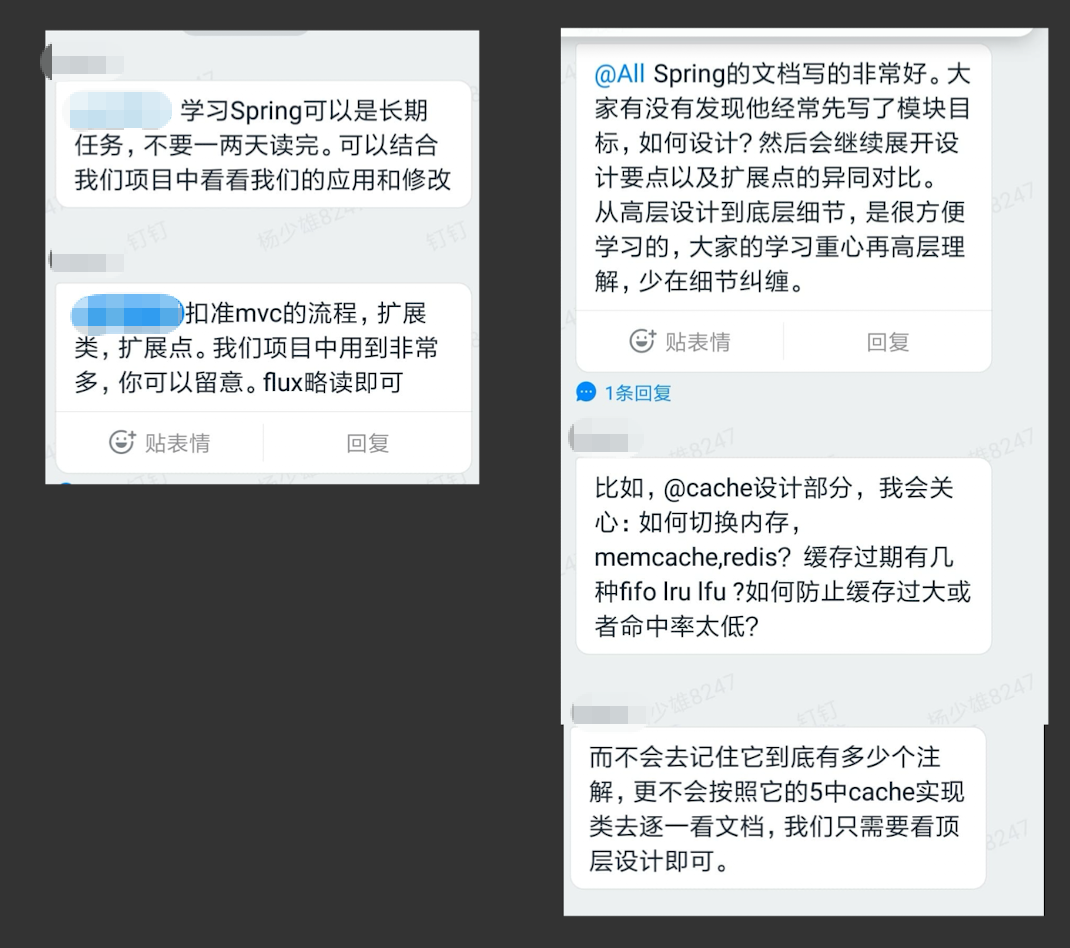
但当我真正去读官方文档,把每一个设计背后的理念、框架的原理和解决问题的思路联系起来时,才发现之前学的那些“步骤”不过是表象的工具,而不是“道”。理解了原理之后,你就能举一反三,不再死板地照搬步骤,而是能根据需求灵活组合、判断、优化
那一周的经历让我明白:学技术不是学会多少框架和操作步骤,而是要理解框架背后的设计思想。这才是真正的核心能力,是你以后无论面对什么新技术,都能快速上手、理清思路的根基
从那以后,我再遇到新的框架或技术时,第一步不是去找教程,而是去读文档、去理解设计理念和解决方案,因为“道”比“术”更重要
一次只做一件事情
解析数据源配置的任务:根据数据接入时为数据源设置的配置项解析它的主键列集合(primaryKeyColumns)和 槽位(buckets),具体要求如下:
- 数据源没有设置配置项时,主键列集合为空数组、槽位为 -1
- 数据源有设置配置项时
- 主键列集合从配置项中直接获取
- 槽位为
tableProps.buckets的值。如果没有这个属性,那么就按主键列集合来解析,主键列集合为空时,buckets为 4,否则就是 16
先看下我的代码,当时的思路是按条件的优先级进行字段值的覆盖
java
public Map<String, Object> queryPartitionBuckets(String domId, String dsId) {
Map result = new HashMap();
result.put("primaryKeyColumns", Collections.emptyList());
Record r = DataSource.dao().getConfigByNodeId(domId, dsId);
if (r == null) {
throw new BIException("cannot find datasource");
}
Map config = JsonUtils.parse(r.getStr("config"), Map.class);
if (config == null) {
result.put("buckets", -1);
return result;
}
// buckets 不存在
List primaryKeyColumns = (List) config.get("primaryKeyColumns");
if (CollectionUtils.isEmpty(primaryKeyColumns)) {
result.put("buckets", 4);
}
else {
result.put("buckets", 16);
result.put("primaryKeyColumns", primaryKeyColumns);
}
Map tableProps = (Map) config.get("tableProps");
if (tableProps != null) {
Integer buckets = (Integer) tableProps.get("buckets");
if (buckets != null) {
result.put("buckets", buckets);
}
}
return result;
}大佬写的代码
java
public Map<String, Object> queryPartitionBuckets(String domId, String dsId) {
Map result = new HashMap();
DataSource ds = DataSource.dao().queryDataSourceById(domId, dsId);
Map config = ds.getMap("config");
if (config == null) {
result.put("primaryKeyColumns", Collections.emptyList());
result.put("buckets", -1);
return result;
}
List primaryKeyColumns = (List) config.get("primaryKeyColumns");
result.put("primaryKeyColumns", primaryKeyColumns);
if (!result.containsKey("buckets")) {
if (primaryKeyColumns == null || primaryKeyColumns.isEmpty()) {
result.put("buckets", 4);
}
else {
result.put("buckets", 16);
}
}
Map tableProps = (Map) config.get("tableProps");
if (tableProps != null) {
Integer buckets = (Integer) tableProps.get("buckets");
if (buckets != null) {
result.put("buckets", buckets);
}
}
return result;
}大佬的写法比我写的更清晰,因为它把逻辑顺序整理得更自然
先判断配置是否为空,再处理 primaryKeyColumns,最后再处理 buckets,每一步只关注一件事情。这样阅读起来像一条流程线,不需要反复跳来跳去理解覆盖逻辑
另外,大佬的代码减少了重复赋值和交叉逻辑。buckets 的默认值只在最后统一处理,而不是在多个分支中分散覆盖,使意图更加明确,也更容易维护
他这种处理方式保证了结果的健壮性,无论配置是否完整,返回的 primaryKeyColumns 和 buckets 都有明确值,不会出现遗漏或混乱,同时也便于后续扩展规则而不引入 BUG
不要重复造"轮子"
这里的轮子指的是已经实现的方法,而不是某类型的框架或库。添加功能时,先找找看功能是否已经实现了,不要再自己写一块,一定会影响后期的维护工作
我写的代码
java
public Map<String, Object> queryPartitionBuckets(String domId, String dsId) {
...
Record r = DataSource.dao().getConfigByNodeId(domId, dsId);
if (r == null) {
throw new BIException("cannot find datasource");
}
Map config = JsonUtils.parse(r.getStr("config"), Map.class);
...
}大佬写的代码
java
public Map<String, Object> queryPartitionBuckets(String domId, String dsId) {
...
DataSource ds = DataSource.dao().queryDataSourceById(domId, dsId);
Map config = ds.getMap("config");
...
}还是前面那个解析数据源配置的任务,代码库中获取数据源这个操作是非常频繁的,因此直接使用 queryDataSourceById 这个方法就可以行了,这个方法被大量引用。因此我们实现更能时,对于一些比较通用的方法,首先要先去看看是否有现成的实现,而不是直接埋头开干
这样写出来的代码是 BUG 滋生的温床,可能会为后续修改埋雷。例如我这边要求系统中所有的数据源,在使用前都应该去检查数据源是否已失效,如果代码中有很多个实现,那么只要我们改动的时候漏掉了一个,那么 BUG 就来了
培养总结和分享的习惯
平时产生的一些想法,我不希望它们被遗忘,所以会把它们记录在 iPhone 的备忘录里
一般来说,我会将想法是断断续续地记录下来,然后当某个主题的片段到达一定层度的内容后,我会对它们进行归纳总结,然后组织成一篇文章,完成后放在 GitHub 的私有仓库中
我把写的东西都丢在 GitHub 私有仓库的原因是害怕写的东西被别人看见
后来我想了想,觉得这是非常错误的想法,如果我写的内容有问题,那么其它人会帮我指出,我后面就会避免这个问题,这是其一
再者,这样能激励我写出多文章,对我归纳总结的能力和写作水平的提升是一个很大的帮助
打磨阅读源代码的方式
第一次参加分享会时,我的任务是向组内小伙伴们分享业务系统中如何通过作业调度引擎与后端大数据系统交互
这是系统的一个核心模块,由经验丰富的老鸟和大佬开发完成,除了主干流程,异常情况的处理占据了大多数,系统中部分模块使用 Scala 实现,这也增加了理解的难度,阅读并理解这些代码对我们这些应届生是个不小的挑战
阅读代码的方法,我总结了几个步骤:首先,归类代码逻辑,将业务逻辑、控制逻辑、错误处理等分类,排除杂音,这样主要逻辑会更清楚。其次,画图,包括程序流程图、调用时序图、模块组织图等,有助于建立整体结构感。然后,采用从整体到细节的读法,先把全局流程理解清楚,再逐步钻研具体实现。最后,结合 debug 跟踪,加深对运行时流程的理解
在抽象层面,重点关注:
接口抽象定义。 代码里总有各种接口或抽象定义,它们描述了数据结构或业务实体及其关系。理清这些关系,是理解整体逻辑的关键
模块粘合层。 很多代码都是用来粘合模块的,比如中间件、Promise、Callback、代理委托、依赖注入等。理解这些“粘合技术”能帮助你看清模块之间的真实联系,否则平铺直叙的逻辑会被拆散得难以理解
业务流程。 这是代码运行的核心过程。初看时不要纠结细节,而是先在高层面理解整个业务流程、数据如何传递和处理。画流程图或时序图是非常有效的手段
在细节层面,重点关注:
代码逻辑。 分为业务逻辑和控制逻辑。业务逻辑是核心处理,控制逻辑用来管理程序流转,如序列化、远程调用、异步控制、多线程处理、标志位等。将这两种逻辑解耦,可以让代码更清晰易读
出错处理。 按照二八原则,20% 的代码处理正常逻辑,80% 用于处理异常。阅读代码时,可以先关注核心逻辑,暂时忽略复杂的异常处理,以提高效率
数据处理。 DAO、DTO、JSON、XML 等处理数据的冗长代码属于辅助逻辑,可以先略过,聚焦核心流程
通过这种方法,我们既能快速把握系统的整体逻辑,也能逐步深入细节,理解业务流程、模块关系和关键逻辑,最终形成对整个系统清晰的认知
写在最后
经过这些,我逐渐明白:技术的成长,本质上是从"术"到"道"的转变。从死记硬背框架步骤,到理解设计思想;从堆砌代码功能,到追求清晰简洁的表达;从闭门造车,到与高手切磋、分享交流
真正的技术能力,不在于掌握了多少工具和框架,而在于能否透过现象看本质,理解问题背后的原理和设计思路。这种思维方式一旦形成,就能在面对任何新技术时快速上手,在面对复杂问题时找到清晰的解决路径
更重要的是,这种思维方式是触类旁通的。它不仅能提升你的技术水平,更能影响你分析问题、解决问题的整体能力。正如文章开头所说:"勿以技术论学识。" 技术只是表象,背后的思维方式才是真正的学识
愿我们都能在技术的道路上,不断打磨自己的思维方式,从"术"的层面跃升到"道"的境界
以上