Skip to content
整洁代码的思考
还记得刚开始实习的时候,无意间翻到一本书——《重构:改善既有代码的设计》,那一刻让我有点震撼。原来代码还能这么写,这么改,甚至还可以改得那么优雅、那么克制。那是我第一次意识到,编程不只是让功能跑起来,它也可以是一门讲究结构与美感的手艺活儿
这本书对我影响最大的,并不是里面列的那些技巧清单,而是作者那种“把代码当成作品来雕琢”的思维方式。真不夸张,你能感受到作者对整洁代码的执念,甚至能从字里行间读出一种工匠精神。那时候我才明白,为什么有人会说国外这帮人是在把编程当艺术来搞
这书有两个版本,一版用 Java 举例,一版用 JavaScript。后者多了些新技术点,比如 Pipeline 模式等,算是更贴近现代编程语言。但不管用什么语言举例,核心思想其实没变:让代码结构更清晰、意图更明确,降低后期维护和扩展的成本
虽然这两本书都不厚,但我一直读到现在。每隔一段时间重读一遍,总能读出点新的味道,就像老电影一样,看第二遍、第三遍,你才会发现原来那些设计藏得这么深、这么巧
而本文正是我平时编码时,针对一些比较实用的重构技术进行的一个归纳总结

在开始总结我自己实战中常用的那些重构技巧之前,我想先聊聊一个核心概念:抽象
可以说,整本《重构》围绕的其实就是这两个字。重构不是简单的变量改名或者函数拆分,而是一次次向更好的抽象靠近的过程。抽象可以是模块、类、函数、接口,也可以是整个子系统——它的目标只有一个:隔离复杂度,把“做什么”和“怎么做”分开,让复杂系统变得可控、可扩展、可理解
而今天我们关注的也正是数据抽象,那什么是数据抽象呢?
数据抽象:将复杂数据的使用和它的构造分离开来,数据结构用于定义数据的构造,数据接口用于定义数据的使用。通过隐藏数据对象的内部特征,定义数据的外部使用,大大降低系统的复杂度
打个比方,重构就像整理工具箱。所有的功能就像工具间里摆放着的各种各样的工具,等着上层业务来对它们进行编排。 工具与工具之间或者说模块与模块之间互不依赖,如果它们要建立联系,就得像工业化生产一样,依赖于一个标准的协议或是接口,而不是具体的实现和数据去完成
你说这些道理大家懂不懂?大多数搞 Java Web 的人,其实都懂。类、接口、分层、职责隔离这些词谁没听过?但真到了项目里,多数人的写法是——Service 层堆逻辑,Controller 里塞判断,抽象和封装听起来“太虚”,赶工才是第一要务
项目赶、需求急、bug 多、上线还得盯着,这种时候谁还管你什么“整洁代码”?有时候你跟人聊这些话题,对方可能还觉得你在装:“写个业务而已,至于么?”我懂,我也经历过这种阶段。但说实话,等你自己被一坨没人愿意维护的烂代码反复折磨之后,你就知道重构和抽象不是情怀,而是续命
至于我们为什么一定要抽象?这事我打算放到文章最后再讲。因为答案其实不在书上,而藏在你亲手维护过的那些代码里
下面就开始进入正文,我总结了几个日常编码中最常见、也最值得一改的场景,顺便带你看看,这些重构技巧到底怎么在项目里落地,才能写出一套让自己都满意的代码
重构技术 1:抽取函数
函数也可以是一种抽象,将如何做的代码封装在函数体内,然后通过函数名来暴露意图
先看一个例子:
java
public class List {
public void add(Object element) {
if (!readOnly) {
int newSize = size + 1;
if (newSize > elements.length) {
Object[] newElements = new Object[elements.length + 10];
for (int i = 0; i < size; i++) {
newElements[i] = elements[i];
}
elements = newElements;
}
elements[size++] = element;
}
}
}你需要花多少时间,才能理解上面的代码呢?这段代码基于数组实现了一个支持自动扩容 List 的新增元素操作。上面的代码没有做任何的抽象,直接把实现的逻辑全部干在 add(el) 这个函数里
下面我们来看看有做数据抽象的版本:
java
public class List {
public void add(Object element) {
if (readOnly) {
return;
}
if (atCapacity()) {
grow();
}
addElement(element);
}
private addElement(Object Element) {
elements[size++] = element;
}
}怎么样,这个 add(el) 方法是不是有一种恍然大悟的感觉,这仅仅只是一个简单的例子,我想通过这个简单的例子来告诉大家抽象的威力,这种威力在一个庞大的项目里更能体现的淋漓尽致。第二个版本通过卫语句、抽取函数、组合方法对函数进行了改造,函数要干嘛一目了然
当然啦,如果我们想知道这个 List 的底层数据结构是数组还是链表,那么我们可以进入到 addElement(el) 这个抽象层次中去探索,就像看书一样,把关注点放在重要的地方上。而不是一下子直接陷入到细节中,那样容易让人脑袋搞不清楚重点、一片空白
通过抽取函数这个重构技术,我们把每次要做的事情封装到一个更小的方法中,从而得到一系列小方法,通过组合这些小方法,来实现整个功能,这种技术叫做组合方法
组合方法的名称描述了它实现了什么功能,而它的方法体则描述了它如何实现这一功能。
好的组合方法的代码都在细节的同一层面上
抽取函数与 Spring 的声明式事务
基于 Spring 或者 Spring Boot 做开发时,经常碰到需要在同一个事务中控制多个副作用,这时候如果使用抽取函数将副作用抽取成成员函数,那么就会导致 Spring 的声明式事务失效,因为 Spring 的声明式事务是基于 AOP 动态代理实现的,因此我们必须通过对象通知的方式才能让 Spring 的声明式事务起作用
通常来说,有三种解决方案:
- 把自己注入自己
- 从 Spring 的 AOP 上下文中获取
- 改用编程式事务
说真的,这上面这三种方式,都可以解决问题,但是我觉得都不够好,为了解决一个这么普遍的问题,引入了那么多"控制逻辑",如果业务中很多这种情况,那么每一个业务层都要通过增加这种控制逻辑来解决问题,重复代码就出现了,系统的复杂度就上去了...
我在平时编码时,发现了一种更好的方式,那就是将副作用上推到业务的抽象顶层
什么意思呢?实际上就是,你依然可以使用抽象函数这种重构技术,区别就是当你需要操作副作用时,可以将组合方法中处理后的数据结果返回给顶层抽象,就是最外边那个有事务控制的函数,在外边操作副作用,就可以很好地绕开这个问题了,而你有没有什么损失,简直一举两得啊
命名好难啊
为一个变量、函数、类等软件起一个名字有多难呢?
There are only two hard things in Computer Science: cache invalidation and naming things.
-- Phil Karlton
Phil Karlton 这个老哥在国外软件工程圈子中是一个响当当的人物,他曾经说过计算机科学中只有两个难题,命名和缓存失效。哈哈哈,我们这里就不去讨论计算机科学中是否只有两个难题,而是要通过这句话意识到命名是一个很重要的话题
命名技术需要通过阅读大量优秀的代码、编写大量代码,然后再实践中进行归纳总结,是无法一蹴而就的。因此这里我主要分享下,我平时如何学习命名的一些方法:
命名 kata 1:了解相关的编码规约、成熟的最佳实践
命名 kata 2:到开源社区中找答案
可以去社区看一些大厂的中间件,代码是如何组织的、变量是如何命名的、函数和类是如何做抽象的等
- 阿里巴巴的 Nacos, Sentinel
- Spring
- Kubernetes
如果你够仔细,那么你会发现大多数函数的命名都是以动词开头的,例如 attach, compose 等
命名 kata 3:A/HC/LC 模式
| Name | Prefix | Action(A) | High Context(HC) | Low Context(LC) |
|---|---|---|---|---|
| getUser | - | get | User | - |
| getUserMessage | - | get | User | Message |
| handleClickOutside | - | handle | Click | Outside |
| shouldDisplayMessage | should | Display | Message | - |
大多数函数的命名都是以动词开头的,就是这里的 Action, 可以是 get, set, reset, fetch(跨网络请求), remove, delete, compose, handle 等
还有 Prefix, 特别是一些返回 true/false 的函数,Prefix 可以是 is, has, should,甚至是 min, max, prev, next 等
重构技术 2:Pipeline 技术
Pipeline 实际上就是一些操作的组合, 第一个操作接收原始数据,并将处理结果返回给下一个操作,以此类推。就像 Shell 的管道符
既然说到 Pipeline,那么有必要炒炒函数式编程的冷饭。函数式编程中有三种非常重要的操作:Map, Reduce, Filter,多数情况下,我们写的程序都是在处理数据,这三种操作可以让我们很方便地进行一些数据的处理
下图很好地比喻了 Map, Reduce 的业务语义:
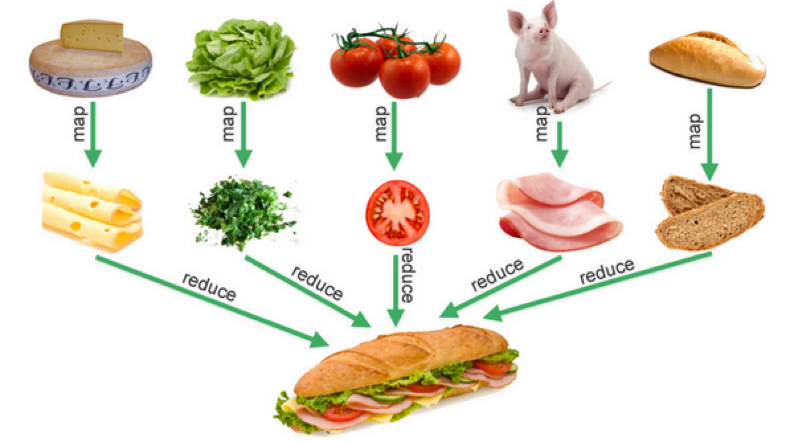
实际上 Map, Reduce, Filter 只是一种控制逻辑,真正的业务逻辑是在传给他们的数据和那个函数来定义的。这是一个很经典的"业务逻辑"和"控制逻辑"分离解耦的编程模式。关于控制逻辑和业务逻辑的区别这个话题,我还会再写一篇文章来做探讨
使用 Pipeline 来分离控制逻辑和业务逻辑
案例:房产管理系统调用 58 同城开发平台接口,接口响应当前房产中介公司的经纪人列表,通过当前经纪人的手机号码解析出经纪人 ID,这边我们可以使用 Pipeline 技术来处理数据
HTTP 响应数据结构:
json
{
"code": 1,
"msg": "success",
"data": {
"dataList": [
{
"username": "Luca",
"md5mobile": "",
"customerId": "1000"
},
{
"username": "Allen",
"md5mobile": "",
"customerId": "1001"
}
],
"totalPage": 2
}
}使用 Pipeline 技术来处理数据:
java
public class AgentPageResponse {
public Optional<String> getCustomerIdOfAgent(String phone) {
Assert.notNull(phone, "phone");
return getAgentPage()
// 通过nullObject链接
.orElseGet(AgentPage::nullObject)
.getDataList()
.stream()
.filter(agent -> agent.isSelf(phone))
.map(FtxAgent::getCustomerId)
.findFirst();
}
}这种 Pipeline 代码的最大的特点就是链式风格,这里我们主要关心 filter 和 map 这两个声明式的操作。filter, map 这些操作属于控制逻辑,而传递给这个操作的数据、代码就是业务逻辑
重构技术 3:封装条件表达式
条件表达式的种类:
| - | 分支多 | 分支少 | 分支体很长 | 分支体短 | 异常分支 |
|---|---|---|---|---|---|
| ✅ | Map | 卫语句 | 多态、命令对象 | Map 配合 lambda 表达式 | 卫语句 |
| 不推荐 | 多态 | Map | - | - | - |
- 分解条件表达式
- 合并条件表达式
- 合并条件体内重复的片段
- 移除控制标记(flag)
- 卫语句
- 多态
- Null 对象
- 断言 -> 契约驱动设计
演示并说明:大雁计算用户退款金额接口的部分代码
重构技术 4:替换算法
替换算法的主要思想是使用简洁、直观的方式实现功能,遵循 KISS 原则、YAGNI 原则,减少程序的复杂度,例如更少分支,让人能看到程序执行的条理性、尽量使用 Map 的原子操作(putIfAbsent 等)
举例:使用 Map 替换双重 for 循环
由于 2.0 系统版本新增了 Adb 和 TiDB 存储引擎,因此后端系统中涉及直接操作存储引擎的模块都需要进行扩展
容量管理的代码是架构师亲自写的,在分析代码的过程中,我无意中发现了他使用的一种算法,这个过程影响了我写代码的思维
容量管理的意义是把数据表的部分元数据,和每张数据表在 SnappyData 中的物理存储信息一起查询出来、做统计等,让用户知道系统中数据表的占用率,用户可以根据这个比例判断是否需要升级存储空间
这样我的需要的数据就有两部分:
- 数据表的元数据存储在 MySQL 中 Datasource
- 数据表的占用磁盘和分区数存储在 SnappyData 的系统表里中 DatasourceStoreInfo
简化下代码,流程大概是这样的:
java
public List<DatasourceStoreInfo> getDatasourceStoreInfo() {
List<DatasourceStoreInfo> datasourceStoreInfoList = queryStoreInfoBy(
domId, searchKey, pageNum, pageSize);
// 构建查询表
Map<String, DatasourceStoreInfo> queryTable = new HashMap();
for (DatasourceStoreInfo storeInfo : datasourceStoreInfoList) {
queryTable.put(storeInfo.getStorageId(), storeInfo);
}
List<Datasource> datasources = queryDatasourceBy(queryTable.keySet());
for (Datasource datasource : datasources) {
DatasourceStoreInfo storeInfo = queryTable.get(datasource.getStorageId());
if (storeInfo == null) {
continue;
}
storeInfo.set("name", datasource.getName());
storeInfo.set("dsId", datasource.getDsId());
storeInfo.set("primaryKeys", datasource.getPrimaryKeys());
}
return datasourceStoreInfoList;
}上面的代码涉及到日常开发中的一种需求:将集合 A 的字段 A1 设置到集合 B 的 B1 字段,通常还需要进行条件判断
在处理上述问题时,经验比较少的开发想到的一般是直接上双重 for 循环,上面这种算法在这种场景下可以说是完胜。通过以空间换时间的方式,这种算法可以高效地提升查询的速度。我觉得这个算法很实用,就给它起名为使用 QueryTable 替代双重 for 循环
我们可以假设集合 A 和集合 B 各有 1000 个元素,那么双重 for 循环就得执行 1000000 次,而使用 QueryTable 只需要执行 2000 次!这让我感触很深,数据结构和算法的用途就在这儿!根据不同的场景使用不同的数据结构和算法,能够高效地提升应用的性能,反之错误地使用它们就会导致系统瓶颈。一个有素养的开发者必须具备这种识别能力!
这个算法在这基础上还能进行优化。配合 JDK8 提供的 Map 新方法 getOrDefault(key, defaultValue)能够减少条件判断的逻辑,在保证可读的前提下,简化代码库。哈哈哈,这下代码不仅变得更高效,而且也变得更简洁了。(没有嵌套、代码量更少)
Map 能分解嵌套 for 循环,这就意味着减少了程序的控制逻辑,而且业务开发情境下,单个 for 循环更容易发现对象间的职责,这样一来我们还可以使用 LoD 技术做进一步的抽象。(见重构技术 6:LoD)
重构技术 5:通过方法重载增强功能
如果功能的某些步骤是可选的,那么我们最好不要使用一堆的 if-else-elif 来处理这些可选步骤,相信我如果你全都 if-else-elif 那简直是在给自己或别人挖坑!
如果你身上唯一的工具是把锤子,那么你会把所有的问题都看成钉子。
Java 里的方法重载这种编程技术可以看做是一层很薄的抽象。我们就可以使用这种技术来处理这些可选的步骤。如果你有看过阿里巴巴一些基于 Java 的开源中间件,那么你会发现它的代码库中很多地方就是使用重载技术来处理一些可选的步骤
跟方法重载最类似的技术就是静态代理、动态代理(AOP)等,但是方法重载的复杂度是最低的,适合封装单个可选步骤。而 AOP 通常封装的单元为比较大,因此也会更复杂一点
案例:微信退款支持错误告警
java
public class WechatService {
public RefundResponse refund(RefundRequest req) {
// biz logic
return resp;
}
/** 通过方法重载增强退款功能, 支持错误告警 */
public RefundResponse refund(RefundRequest req, Long userId) {
RefundResponse resp;
try {
resp = refund(params);
}
catch (Exception e) {
dingding.pushErrorAlert(e.getMessage, userId);
throw e;
}
return resp;
}
}这样一来业务编排层就不需要再关心 非业务情况下请求失败 的错误处理,只需要专注地处理具体业务就行
重构技术 6:迪米特法则(LoD)
java
for (CorpCooperation corp : corpCooperationList) {
CooInitDataVO cooInitDataVO = authForm.get(corp.getNetId());
if (cooInitDataVO == null) {
continue;
}
// 房源有在这个外网发布
HousePushDetail housePushDetail = housePushDetailTable.get(netId);
if (Objects.nonNull(housePushDetail)) {
HousePushDetailDTO dto = housePushDetailAssembler.toDto(housePushDetail)
cooInitDataVO.setPushDetail(dto);
}
// 当前用户的认领信息
List<UserClaimHouseDTO> userClaimHouseDTOList = userHouseClaimTable.get(netId);
List<AccountDTO> accountDtoList;
if (CollectionUtils.isEmpty(userClaimHouseDTOList)) {
accountDtoList = Collections.emptyList();
}
else {
accountDtoList = AccountAssembler.toDtoList(userClaimHouseDTOList);
}
cooInitDataVO.setAccountList(accountDtoList);
authForm.put(netId, cooInitDataVO);
}改造后:
java
for (CorpCooperation corp : corpCooperationList) {
CooInitDataVO cooInitDataVO = authForm.get(corp.getNetId());
if (cooInitDataVO == null) {
continue;
}
HousePushDetail housePushDetail = housePushDetailTable.get(netId);
cooInitDataVO.applyPushDetail(housePushDetail);
// 当前用户的认领信息
List<UserClaimHouseDTO> userClaimHouseDTOList = userHouseClaimTable.get(netId);
cooInitDataVO.applyAccountList(userClaimHouseDTOList);
authForm.put(netId, cooInitDataVO);
}LoD 实际上就是面向对象的迪米特法则,即单个模块不应该知道得太多东西、小粒度的类
在 for 循环体内是很容易发觉对象的职责的!这时候你就可以使用 LoD 技术进行重构。再来看看下面这个计算套餐退款金额的逻辑:
java
BigDecimal totalPrice = BigDecimal.ZERO;
for (Order order: orders) {
if (remainingDay.isNoDays()) {
// 剩余天数为0时,无需继续计算。不统计已被使用的套餐
break;
}
if (order.isFreePackage()) {
remainingDay.decrementRemainingDays(order.getAmount());
continue;
}
if (order.isAdminOperation() || order.isExpired() || order.isFromSms()) {
PayRefund payRefund = assembler.toUserCannotRefund(userId, remainingDay);
payRefundMapper.insert(payRefund);
return;
}
BigDecimal priceOfPerOrder = order.calcRefundAmount(remainingDay);
totalPrice = totalPrice.add(priceOfPerOrder);
}上面这段代码使用封装了订单的各种条件判断逻辑,退款金额的计算逻辑被封装到了 Order#calcRefundAmount 中,代码位于业务编排,就像我之前说过的那样,业务编排层仅仅负责对模块进行编排,基本上都是对象通知的代码,细节都被封装到了模块内部
原因:
- 模块内聚性更高: 合理使用可以减少重复代码, 使得模块间松散耦合, 避免散弹式修改
- 减少业务编排层的大量控制逻辑
- 测试友好: 方便 Stub, Mock
时机:
- 注意被迭代的对象或迭代体内的对象
- LoD 不适于函数式编程 [^2]
举例说明
PayRefundServiceImpl:105CorpCooperationServiceImpl:297
重构技术 7:分离数据结构和操作
使用访问者模式解耦数据结构和算法
Visitor 是面向对象中的一个很重要的设计模式,这个模式是一种将算法与操作对象的结构分离的一种方法。这种分离的实际结果是能够在不修改结构的情况下向现有对象结构添加新操作,是遵循开封原则的一种方法
kubectl 是 Kubernetes 中的一个客户端命令,操作人员用这个命令来操作 Kubernetes。kubectl 会联系到 Kubernetes 的 API Server,API Server 会联系每个节点上的 kubelet ,从而达到控制每个结点。kubectl 主要的工作是处理用户提交的东西(包括,命令行参数,yaml 文件等),然后其会把用户提交的这些东西组织成一个数据结构体,然后把其发送给 API Server
kubectl 的代码比较复杂,不过,其本原理简单来说,它从命令行和 yaml 文件中获取信息,通过 Builder 模式并把其转成一系列的资源,最后用 Visitor 模式模式来迭代处理这些 Reources
go
type DecoratedVisitor struct {
visitor Visitor
decorators []VisitorFunc
}
func NewDecoratedVisitor(v Visitor, fn ...VisitorFunc) Visitor {
if len(fn) == 0 {
return v
}
return DecoratedVisitor{v, fn}
}
// Visit implements Visitor
func (v DecoratedVisitor) Visit(fn VisitorFunc) error {
return v.visitor.Visit(func(info *Info, err error) error {
if err != nil {
return err
}
if err := fn(info, nil); err != nil {
return err
}
for i := range v.decorators {
if err := v.decorators[i](info, nil); err != nil {
return err
}
}
return nil
})
}对于 Kubernetes,其抽象了很多种的 Resource,比如:Pod, ReplicaSet, ConfigMap, Volumes, Namespace, Roles …. 种类非常繁多,这些东西构成为了 Kubernetes 的数据模型
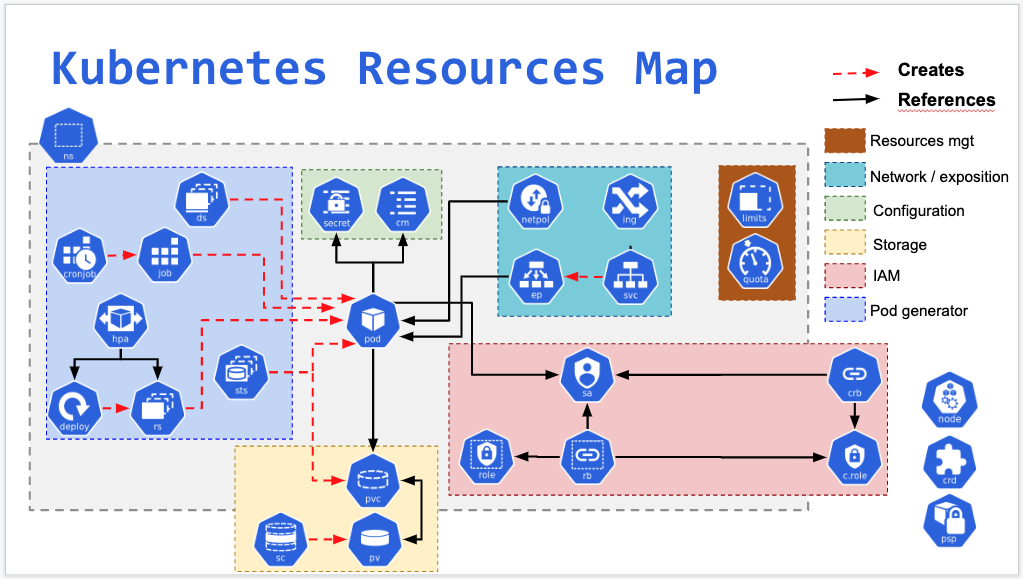
最后
下面来填文章开头那个坑,我们为什么要耗费精力做抽象呢?
- 可读性与扩展性。抽象让代码逻辑清晰,层次分明,方便理解和扩展
- 维护性与快速定位问题。结构化的抽象让问题易于隔离,通过堆栈就能快速定位源头
- 可重用与解耦。小而独立的模块设计目的就是可重用,同时降低各部分耦合度,提高整体灵活性
- 易于测试。抽象使得依赖可 Mock,底层逻辑可独立验证,测试更简单、可靠
以上