Skip to content
Kafka 如何做到高吞吐高可用?
Apache Kafka 作为业界领先的分布式流处理平台,以其出色的高可用性和高吞吐量特性而闻名,在现代分布式系统中扮演着至关重要的角色
那么,Kafka 是如何实现这两个核心能力的呢?
核心设计理念
Kafka 的高可用和高吞吐并非偶然,而是通过精心设计的核心概念协同工作实现的
高可用与高吞吐的协同设计。通过主题、分区、副本、Broker 和消费者组等核心概念的协同工作,Kafka 实现了高可用和高吞吐的完美结合:
- 高吞吐:通过分区机制实现并行读写,通过消费者组实现并行消费,通过多 Broker 集群实现横向扩展
- 高可用:通过副本机制实现数据冗余和自动故障转移,通过多 Broker 部署避免单点故障
这种设计使得 Kafka 能够同时处理海量消息,并在面对硬件故障时保持服务不中断
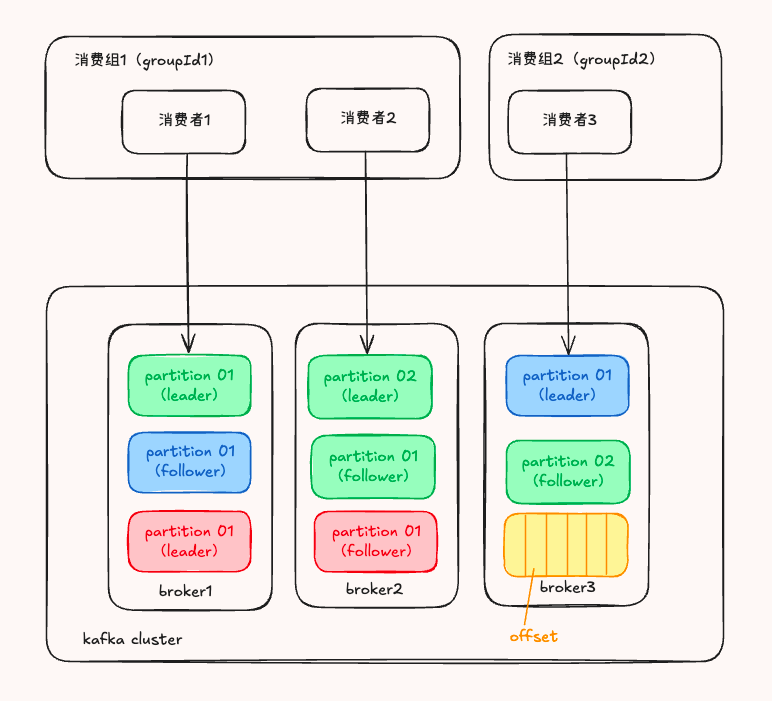
主题(Topic):消息的逻辑分类
主题是消息的逻辑分类单位,类似于传统消息队列中的队列概念。所有消息都必须发布到某个 Topic 上,消费者则从指定的 Topic 中订阅消息
一个 Topic 可以被物理划分为多个分区(Partition),这种设计为后续的并行处理和横向扩展奠定了基础。不同的业务场景可以使用不同的 Topic 来隔离消息,比如订单系统使用 order-topic,日志系统使用 log-topic
分区(Partition):实现高吞吐的关键
分区是 Kafka 实现高吞吐量的核心机制。可以把它想象成主题的"子文件夹",每个分区在物理上是一个有序的日志文件
分区如何提升吞吐量?
- 并行读写:多个分区可以分布在不同的 Broker 上,生产者和消费者可以同时向多个分区写入和读取数据,从而实现并行处理
- 横向扩展:当单个 Broker 的处理能力不足时,可以通过增加分区数量来提升整体吞吐量,而不需要替换硬件
- 负载均衡:多个消费者可以并行消费不同分区的数据,充分利用系统资源
分区的有序性保证:虽然不同分区之间的消息顺序是独立的,但同一个分区内的消息是有序的。这种设计在保证顺序性的同时,也实现了并行处理
偏移量(Offset):每条消息在分区中都有一个唯一的偏移量,这是一个单调递增的整数。Offset 就像"追剧记录",它记录消费者在每个分区中读取到哪个位置。Kafka 不会主动删除消息(除非达到保留策略),它只关心:"你上次看到哪了?"这样消费者可以随时从上次中断的位置继续消费,也可以回溯到任意历史位置重新消费
值得注意的是,每个消费者组在每个分区中都有自己独立的 Offset,这意味着不同的消费者组可以独立消费同一个 Topic,互不干扰
副本(Replication):保障高可用的基石
副本机制是 Kafka 实现高可用的核心。每个分区可以有多个副本,这些副本分为两种角色:
- Leader Replica:负责处理所有的读写请求,是分区的"主节点"
- Follower Replica:负责从 Leader 同步数据,作为备份存在
副本如何保障高可用?
- 数据冗余:多个副本意味着数据有多份备份,即使某个 Broker 宕机,数据也不会丢失
- 自动故障转移:当 Leader 副本所在的 Broker 发生故障时,Kafka 会自动从 Follower 副本中选举出新的 Leader,整个过程对客户端透明,保证了服务的连续性
- 分布式存储:Kafka 有一个重要的设计原则:同一个分区的多个副本必须分布在不同的 Broker 上。这样可以避免单点故障,即使某个 Broker 完全宕机,其他 Broker 上的副本仍然可以继续提供服务
副本数量通常配置为 3(1 个 Leader + 2 个 Follower),这样即使一个 Broker 宕机,系统仍然可以正常运行
节点(Broker):Kafka 集群的节点
Broker 是 Kafka 的服务器节点,负责消息的存储、转发和管理。多个 Broker 组成一个 Kafka 集群,共同提供高可用和高性能的消息服务
在实际生产环境中,通常会部署多个 Broker 来构建集群。例如:"目前我们集群跑 5 个 Broker,每个 Topic 配了 6 个 Partition,负载均衡挺稳。"这样的配置可以同时保证高可用(多个 Broker 容错)和高吞吐(多个分区并行处理)
消费者组(Consumer Group):实现负载均衡消费
消费者组是一组具有相同 groupId 的消费者,它们协同工作来实现负载均衡的消息消费
消费者组的工作机制:
- 分区分配:Kafka 会将 Topic 的各个分区分配给消费者组中的不同消费者,确保每个分区只被组内的一个消费者消费,避免重复消费
- 并行消费:同一个消费者组中的不同消费者可以并行消费同一个 Topic 的不同分区,这是 Kafka 实现高吞吐量的另一个重要原因
- 动态扩展:当消费者组中的消费者数量发生变化时(新增或移除),Kafka 会自动重新分配分区,实现动态负载均衡
这种设计使得消费者组可以轻松实现水平扩展:当消费速度跟不上生产速度时,只需要增加消费者组中的消费者数量,Kafka 会自动将分区重新分配,提升整体消费能力
实践:本地启动 Kafka
让我们通过实践来加深理解。下面是一个使用 Docker Compose 启动 Kafka 的最小化方案,适合本地开发和测试
Docker Compose 配置
这个配置包含了 Kafka 运行所需的最基本组件:ZooKeeper(用于元数据管理)和 Kafka Broker
yaml
version: "3.8"
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.5.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: confluentinc/cp-kafka:7.5.0
hostname: kafka
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1启动服务
使用以下命令启动 Kafka 和 ZooKeeper:
sh
docker-compose up -d验证 Kafka 运行
启动成功后,我们可以通过 Kafka 自带的命令行工具来验证和操作 Kafka
- 创建主题
首先创建一个测试主题,这里我们创建一个名为 my-topic 的主题,配置 1 个分区和 1 个副本(单机环境):
sh
docker exec -it kafka bash
# 创建一个主题
kafka-topics --create --topic my-topic \
--bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
# 查看主题列表
kafka-topics --list --bootstrap-server localhost:9092- 发送消息(Producer)
使用控制台生产者发送消息:
sh
kafka-console-producer --broker-list localhost:9092 --topic my-topic输入消息后按 Enter 发送,使用 Ctrl+C 结束
- 消费消息(Consumer)
使用控制台消费者接收消息。可以指定从开始位置消费,也可以指定消费者组:
sh
# 从开始位置消费(不指定消费者组)
kafka-console-consumer --bootstrap-server localhost:9092 \
--topic my-topic --from-beginning
# 指定消费者组消费
kafka-console-consumer --bootstrap-server localhost:9092 \
--topic my-topic --group my-group --from-beginning清理环境
测试完成后,可以使用以下命令停止并清理容器和数据卷:
sh
docker-compose down -vKafka 客户端工具
虽然命令行工具功能强大,但在实际工作中,使用图形化界面可以更直观地查看和管理 Kafka。下面介绍几个常用的工具
Redpanda Console
Redpanda Console 是一个现代化的 Kafka Web UI,提供了直观的界面来查看主题、分区、消费者组等信息
使用 Docker 快速启动:
sh
docker run -d -p 8080:8080 \
-e KAFKA_BROKERS=10.64.124.198:9092,10.64.124.197:9092,10.64.124.199:9092 \
docker.redpanda.com/redpandadata/console:latest启动后访问 http://localhost:8080 即可使用
Kafka Tool (Offset Explorer)
Kafka Tool 是一个桌面应用程序,提供了丰富的功能来管理 Kafka 集群,包括查看主题、分区、消息内容、消费者组状态等
kcat
kcat(原 kafkacat)是一个的命令行工具,可以用于生产、消费和查询 Kafka 消息
基本消费示例:
sh
# 消费指定主题的消息
kcat -C -b 10.64.124.198:9092,10.64.124.197:9092,10.64.124.199:9092 \
-t dy-changjing-live-barrage高级用法:
sh
# 过滤数据:从开始位置读取并过滤特定内容
kcat -C -b 10.64.124.198:9092,10.64.124.197:9092,10.64.124.199:9092 \
-q -o beginning \
-t dy-changjing-live-barrage | grep -e "珍"
# 从头开始读取消息(静默模式,只输出消息内容)
kcat -C -b 10.64.124.198:9092,10.64.124.197:9092,10.64.124.199:9092 \
-t dy-changjing-live-barrage -o beginning -q
# 读取最新消息
kcat -C -b 10.64.124.198:9092,10.64.124.197:9092,10.64.124.199:9092 \
-t dy-changjing-live-barrage -o end
# 读取最近 10 条消息
kcat -C -b 10.64.124.198:9092,10.64.124.197:9092,10.64.124.199:9092 \
-t dy-changjing-live-barrage -o end -c 10可以说,GUI 工具适合日常管理和监控,命令行工具则更适合自动化脚本和快速调试
总结
Kafka 之所以能够实现高可用和高吞吐,源于其精心设计的架构:
- 分区机制:实现了并行处理和横向扩展,通过将数据分散到多个分区,充分利用多核 CPU 和网络带宽,大幅提升吞吐量
- 副本机制:保障了数据安全和服务连续性,通过多副本冗余和自动故障转移,即使部分节点宕机,系统仍能正常运行
- 消费者组:实现了负载均衡的并行消费,通过动态分区分配,可以轻松实现消费能力的水平扩展
- 多 Broker 集群:避免了单点故障,通过分布式部署,提升了系统的整体可用性和处理能力
这些设计理念相互配合,使得 Kafka 能够在处理海量消息的同时,保持极高的可用性。理解这些核心概念,不仅有助于更好地使用 Kafka,也能为设计其他分布式系统提供参考
在实际应用中,我们需要根据业务场景合理配置分区数、副本数和消费者数量,在性能、可用性和资源消耗之间找到平衡点